MaxSea
Machine Learning Specialist • april 2024 - september 2024 (6 month)
Internship • Bidart, Nouvelle-Aquitaine, France
Neural network (YOLOX) training for real time ship detection and tracking.
1. Data gathering
Improving YOLOX performance started by creating a boat detection dataset. I managed to gather more than 110 000 images with about 290 000 ships.
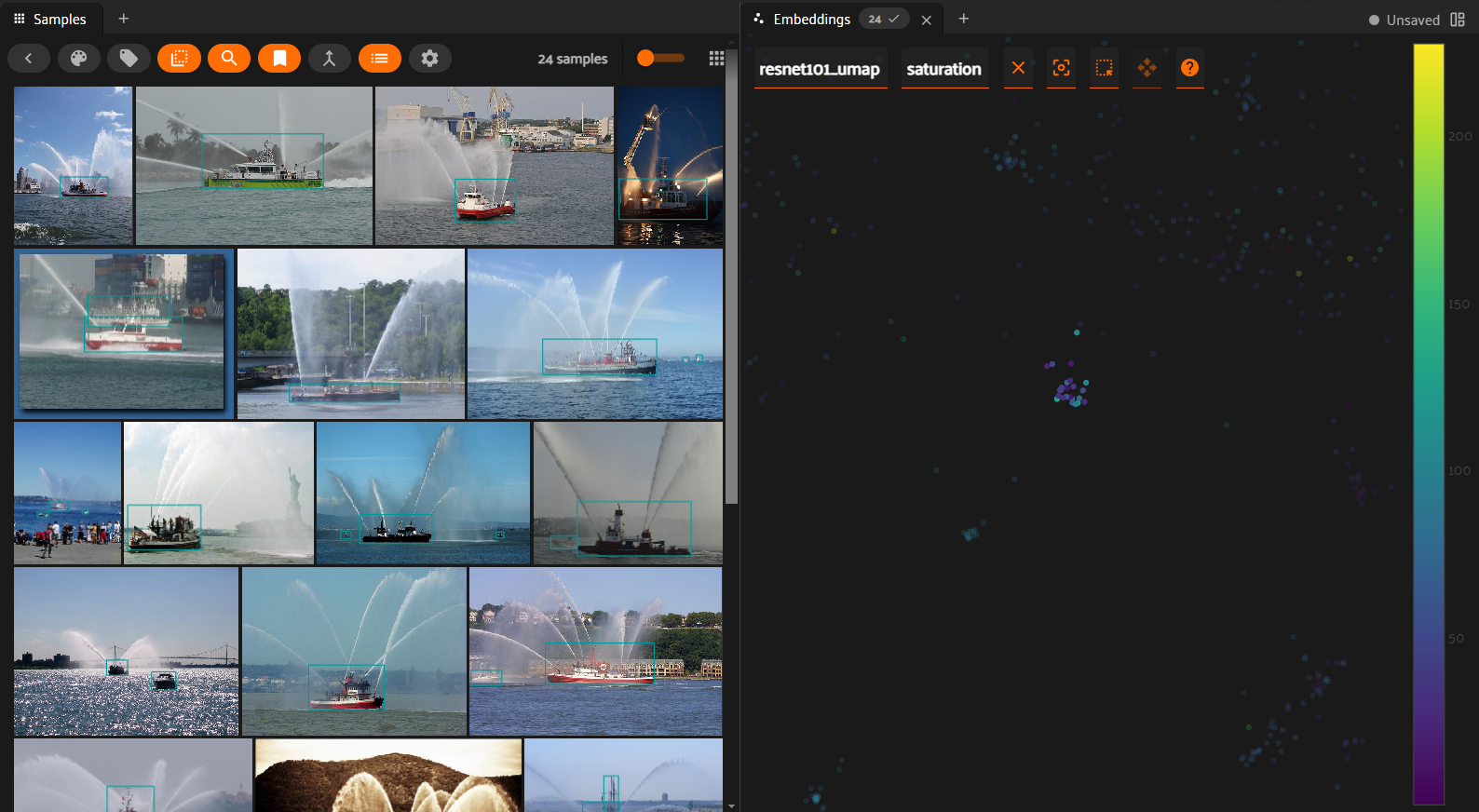
By exploring the dataset with FiftyOne, I detected some duplicates and similar images. Thanks to embeddings, I created a similarity filter that I used to avoir overfitting.
2. Visualization and statistics
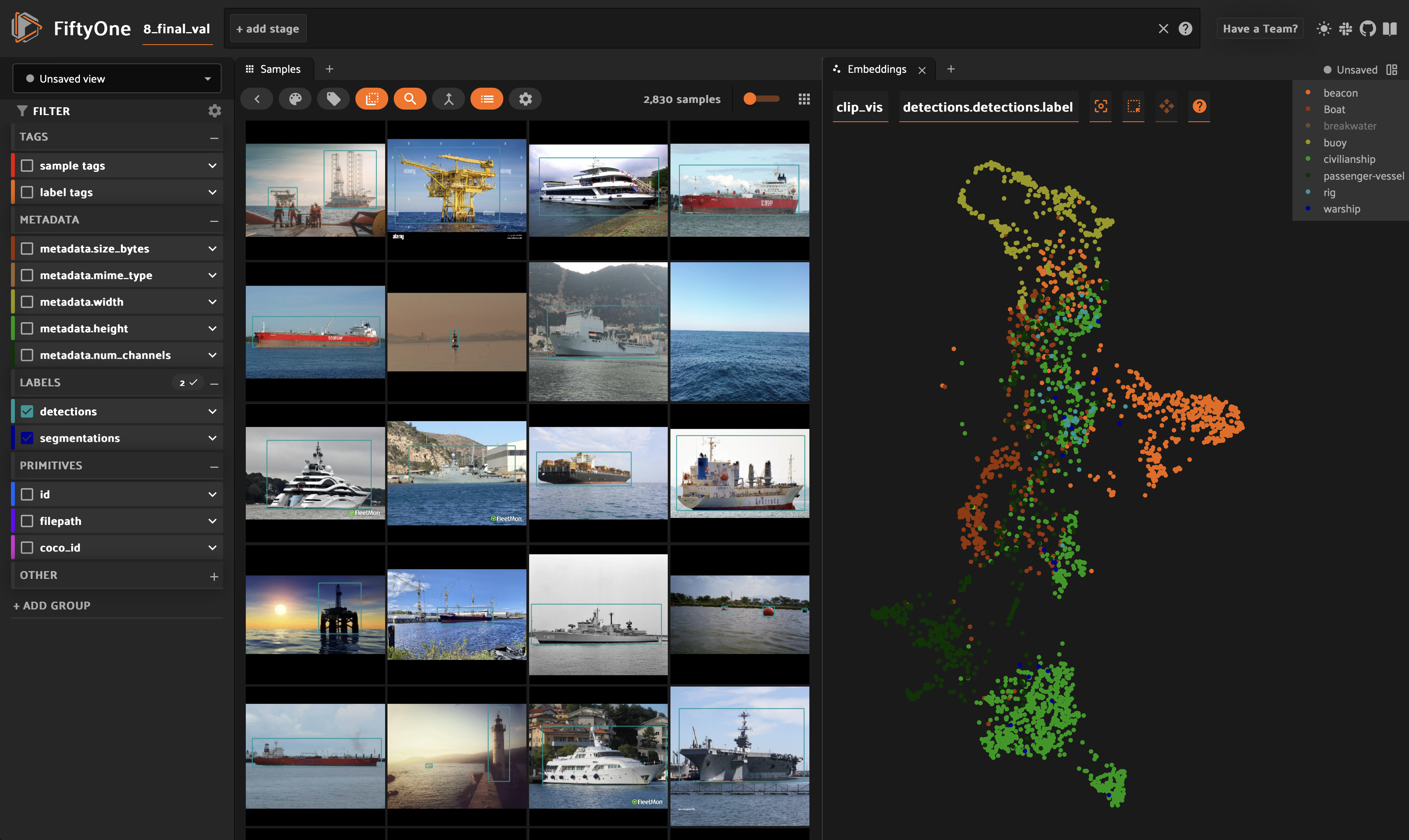
Embeddings allowed me to go deeper into the dataset: I detected clusters of unwanted objects like submarines. I computed statistics on detection size, image dimensions and number of objects per class of boat (to avoid unbalaced categories).
3. Clustering and annotation
To allow the model to classify boats, I labelled the dataset. I used the embeddings and clustering wich allowed me to quickly sort data.
4. Training
To rapidly iterate over experiments, I automated the training pipeline. The pipeline contained data filters, YOLOX paramters, logs and training results backup.
Everything was automated to the team could launch a full training based on a single json file and bash script.
5. Quantization
To allow YOLOX to work real time, I used OpenVINO to quantized every model and optimize it for Intel CPUs. The improvement was above 45% per frame.
6. Performances and tests
To create a solid knowledge based for my successor, I logged every training and create clear reports of my work. The next data scientist could easily work on the project right after me and didn’t need mush time to get to know the processes.
📄 This internship is described in my memoire.
Here are the results of a model I trained. Other smaller models were traing in order to be less ressources heavy.

To efficiently annotate datasets, I used embeddings and FiftyOne. I then created similarity maps :
Here are ships detected as fireboats :